
The publication in February of the Francis Report into the failings of the Mid-Staffordshire NHS Foundation Trust was the worst of the many recent bad news stories about the NHS, its significance underscored by the fact that David Cameron felt it necessary to present the report to the House of the Commons himself, rather than leave it to the secretary of state for health. The public inquiry was set up in 2010 by the then secretary of state, Andrew Lansley, to investigate further the findings of a previous inquiry, commissioned by the Labour health minister Andy Burnham and intended ‘primarily to give those most affected by poor care an opportunity to tell their stories’. Many such stories had been collected by campaigners like Julie Bailey, a café-owner whose mother died in Stafford Hospital after being treated with callous incompetence. In November 2007, Bailey founded a pressure group called Cure the NHS and began to gather reports of patients left to lie for days on urine-soaked beds or allowed to become so thirsty that they drank water from vases of flowers. The statistics presented in the Francis Report suggest that at Mid-Staffs hundreds of patients died who might well have lived had they been treated in a good, or even an average hospital. Some newspapers have consistently claimed that 1200 patients died unnecessarily. It isn’t quite clear how they arrived at this total, and it matters, because the mortality statistics and their reliability are crucial to any assessment of what happened. The method used to arrive at the figures in the Francis Report is complicated, and has its critics. Its origins can be traced back to the inquiry into an earlier scandal, concerning the deaths of children who underwent heart surgery at the Bristol Royal Infirmary between 1991 and 1995.
The initial focus of the Bristol inquiry was the quality of the work of the surgeons who performed open-heart operations, two of whom, James Wisheart and Janardan Dhasmana, were struck off even before Ian Kennedy’s report was published. The problems at the infirmary had become public largely through the efforts of Stephen Bolsin, a consultant anaesthetist with an interest in clinical audit, a process in which clinicians’ outcomes are measured. Bolsin became worried about the competence of these two surgeons to perform some of the more risky operations on small children. When he first told his colleagues about his concerns he was encouraged to drop the matter, but instead he kept collecting data. Convinced that the surgeons’ mortality rates were excessive, he tried again to raise his concerns with senior colleagues, hospital administrators and people outside the hospital. But then the story appeared in the press (Bolsin spoke to a GP who – Bolsin said afterwards he hadn’t known – wrote for Private Eye) and action became inevitable. Bolsin’s audit plays a prominent part in the Kennedy Report, in the story of who knew what when and who should have acted but didn’t. It was perhaps the cause and perhaps the consequence of a breakdown in trust between colleagues, and was vehemently criticised by Wisheart and Dhasmana’s supporters, who called it the ‘secret audit’ and hinted at flaws in the method. But Bolsin’s data are not cited in the Kennedy Report because the inquiry commissioned its own statistical analysis from experts including David Spiegelhalter, now Winton Professor for the Public Understanding of Risk at Cambridge, and Paul Aylin, now the assistant director of the Dr Foster Unit at Imperial College.
You might think that their task was relatively straightforward. After all, the figure that matters here, the mortality rate, is simply the number of patients who died after treatment divided by the number of patients who were treated. But the Bristol mortality rate is of no interest on its own: what matters is how it compares with the rate at other centres. This means that the definitions of the two numbers have to be applied consistently. Again, that might seem pretty straightforward, but it isn’t as simple as it sounds.
The first challenge was to get hold of the data. One option was to use the information known as hospital episode statistics, or HES data, that hospitals have had to return to the NHS since 1987. These allow us to tell whether or not a patient died in hospital, but although they’re supposed to include those who died shortly after discharge, the inquiry found that in Bristol around 5 per cent of those deaths were missing from HES figures. The data are even less reliable when it comes to identifying which patients had which condition or underwent the procedure under investigation. Patients arriving in hospital are given a primary diagnosis by the clinician responsible for their first ‘episode of care’. There might be additional diagnoses, or the original diagnosis might change, but although there might be several ‘episodes of care’ in a single hospital stay, the focus tends to be on the first. When doctors record diagnoses they are free to choose which words to use and their choices can be idiosyncratic. After a patient is discharged the notes are read, often with some difficulty, by a ‘clinical coder’, a relatively low-paid member of the hospital administration whose job it is to match the doctor’s narrative against two lists of standard terms, the World Health Organisation’s International Classification of Diseases (ICD) and the Classification of Interventions and Procedures issued by the Office of Population Censuses and Surveys (OPCS). It is the classification of care using these standard codes that makes HES data appealing to statisticians. The coding, however, is notoriously prone to error (last year’s HES summary statistics record, for instance, that of the 785,263 in-patient episodes coded under Obstetrics, 16,992 were recorded for male patients) and the system wasn’t designed to measure the quality of care, only the quantity.
There are alternative measures. For example, the Society of Cardiothoracic Surgeons of Great Britain and Ireland compiled a UK Cardiac Surgical Register (UKCSR) of anonymised data which covers the period dealt with by the Bristol inquiry. The Bristol statisticians found weaknesses in the UKCSR: units varied in the way they classified personnel, in the source of the data reported and the definitions applied, with the classification of complex diagnoses being a particular problem. It was also sometimes hard to identify which surgical procedure had been performed.
Statisticians refer to a collection of measurements that they are studying as a ‘distribution’. A common task in statistics is to assess whether two samples should be considered as coming from the same distribution. Imagine that, for some reason, one were testing the hypothesis that people in London are taller than those in the rest of the UK. One could select two samples of, say, twenty adults each, one from London and one from the rest of the UK. Even if there was no actual difference between Londoners and the rest of the UK, one wouldn’t expect the average height in the two samples to be exactly the same: the question is whether the detected difference reflects a real underlying difference. In statistical terms, the question is how likely it is that the detected difference in averages between two samples taken from the same distribution could have arisen by chance. Conventionally, if the probability is less than 5 per cent, then the difference is deemed ‘statistically significant’ and reflects a true difference in averages. One way of displaying this is to draw a ‘95 per cent confidence interval’ around each sample’s average, meaning that 95 per cent of the time the true average will be within that range.
The simplest analysis carried out by the statisticians working for the Bristol inquiry was to compare the mortality rate at Bristol with the mortality rate at 11 other centres carrying out similar operations. As in the example above, the mortality data are treated as a sample which provides an uncertain estimate of the centre’s ‘true’ mortality rate, an estimate around which we can calculate a 95 per cent confidence interval. This analysis was of limited value, however, because the surgeons at Bristol maintained that the reason their mortality rate was high was that they carried out riskier operations than other centres. So the statisticians undertook a more sophisticated analysis in which they pooled the data from the other centres and modelled the risk associated with the different factors in play: the age of the patients, the type of operation and the year it was performed. They then calculated, for a hypothetical centre performing the same kinds of operation as Bristol, what the expected mortality would be. According to this analysis, both the UKCSR and the HES showed evidence of excess mortality from 1991 to March 1995 in open-heart operations on children under one year old. In this period, for these children, the mortality rate in Bristol was around double that of other centres. The estimated excess mortality was 19 out of the 43 deaths reported to the CSR and 24 out of the 41 deaths recorded in the HES.
The main analysis used a Bayesian approach to statistics, that is to say one in which data are interpreted as updating our prior beliefs about the world rather than being analysed as if they were all that we knew. This requires the explicit specification of uncertainties in the ‘prior distribution’, i.e. in the statistical model being used. In the Bristol case, a key specification was that the calculation of the risk associated with, for example, one of the types of operation performed should not assume that the risk would be the same in each centre. The approach would have been unfamiliar to many of the doctors reading the report of the Bristol inquiry or the various journal articles in which the work was subsequently published. A letter published in the Lancet in response to the analysis makes the point that while the rigour and complexity of the statistical analysis may have ensured an authoritative answer to the question ‘Was Bristol an outlier?’, that very complexity made it harder to answer the really pressing question: ‘Shouldn’t the Bristol surgeons have known that they were outliers?’
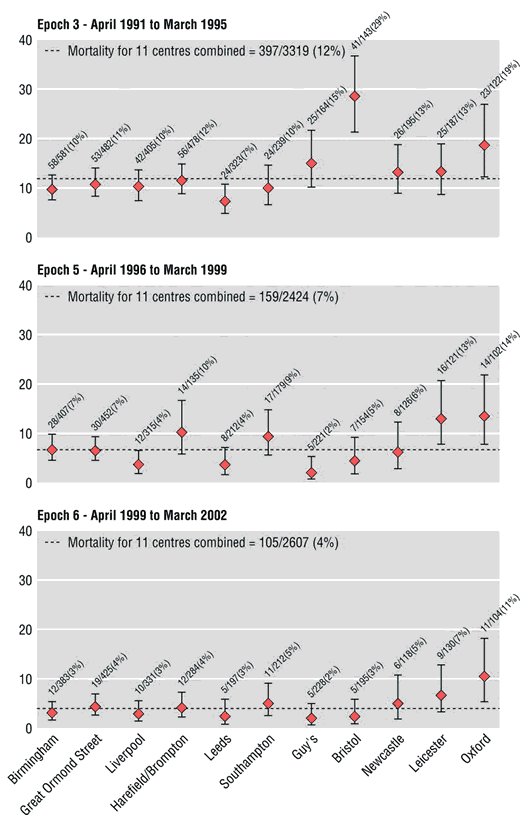
After the Bristol inquiry, statisticians were granted regular updates of HES data, Kennedy having recommended that there should be more openness and transparency. In 2004, Paul Aylin and others, including Brian Jarman, an emeritus professor of primary care at Imperial College who had been on the panel of the Bristol inquiry, published figures in the BMJ comparing the performance of different units doing open-heart surgery on children under one year old during three different time periods. The analysis was based on HES data. On the charts they produced (see below), each unit is represented by a red dot; the position of the dot is the best estimate of the mortality rate; the bars through the dot mark the 95 per cent confidence interval: if the data are accurate and the method unbiased, 95 per cent of the time the true rate will be somewhere in this range. Hospital units are arranged in order of the number of operations performed, with smaller units to the right. The extent to which the performance at Bristol was divergent during the period covered by the inquiry is shown clearly in the chart for Epoch 3. Looking at all three charts, we can see that Oxford too seems something of an outlier. In fact, doctors there were so outraged that their professional competence had been publicly undermined on the basis of something as ropy as HES data that they reported Aylin to the General Medical Council. Their case was dismissed. The Oxford unit is no longer allowed to perform open-heart surgery on children under one.
By the time Kennedy’s report appeared in 2001, Jarman had begun to look at using HES data not just to report on specialist units performing dangerous operations but to measure the performance of hospitals more generally. In 2000, Jarman and Aylin set up the Dr Foster Unit at Imperial College, with the stated aim of applying their developing expertise in the monitoring of mortality, and a separate company called Dr Foster Intelligence (DFI) to exploit the commercial potential of the unit’s work. They developed what they called the Hospital Standardised Mortality Ratio (HSMR), calculated like this: HSMR = (Actual Deaths ÷ Expected Deaths) x 100. The data on actual deaths are taken from HES and restricted to in-hospital deaths, leaving out patients who were admitted for palliative care. To calculate the number of expected deaths in a hospital, first you work out the risk of death associated with particular diagnoses (the HSMR considered only the 56 diagnoses collectively responsible for 80 per cent of admissions), as well as the patients’ age, sex, social deprivation score and type of admission (emergency or elective). The mix of these factors in each hospital is used to calculate the expected death rate. If the expected death rate is the same as the actual death rate, the trust scores 100; actual scores tend to range between 75 and 120. Between 1997 and 2008 the HSMR of Mid-Staffs peaked at 127 and never dropped below 108. In all but two years the lower end of the 95 per cent confidence interval was above 100.
Although the data and the statistical techniques used to calculate the HSMR are similar to those used by Spiegelhalter and Aylin at Bristol, DFI wanted to assess not the performance of a single unit performing a dangerous operation requiring a great deal of technical skill, but the performance of an entire hospital carrying out a wide variety of procedures of differing degrees of complexity and risk – and to do so for every hospital in the NHS. Many were unconvinced. Spiegelhalter was particularly critical of the use of HSMR to compile league tables of hospitals, as DFI began to do in 2001. His reasons can be simply illustrated:
Imagine that these figures were presented as being the percentage mortality rates for paediatric cardiac surgery in ten different hospitals. You would be pretty unhappy to be told that your child was to be treated at hospital A, given the difference between A and G. But in fact I generated the table using a computer program that assumes the probability of mortality in any given operation – in any hospital – is exactly 4 per cent. The more often the program is run, simulating large numbers of operations, the closer the mortality rate in all hospitals will approach that figure, but if you run it just a few times, approximating real sample sizes (I set it to 140 operations per hospital – as many as took place at Bristol between 1991 and 1995), you will see a range like the one above. League tables – applied to surgeons, hospitals or schools – do not give the person reading them any sense of how much variation would be expected for a given sample size and instead impose a rank that the data may not support. There were good reasons for a hospital to regard a poor placing in DFI’s tables as merely an irritating bit of bad publicity.
According to the Francis Report there is no evidence that, despite its consistently poor performance, anyone at Mid-Staffs was aware of the hospital’s HSMR until April 2007, when DFI’s annual Good Hospital Guide was published by the Daily Telegraph showing Mid-Staffs to have an HSMR of 127, a clear outlier and the fourth worst performing trust in the country. On 4 June the trust’s Clinical Quality and Effectiveness Group met and decided, not to check whether or not patients were being looked after properly, but to investigate the coding of their diagnoses. They instructed coders not to use the codes that seemed most responsible for the hospital’s high HSMR. The case notes of patients who had died in the trust’s two hospitals, Stafford and Cannock Chase, were reviewed, but no attempt was made to establish whether there had been any weaknesses in their treatment; again, what was being looked for were possible errors in the coding. Nine out of the 14 deaths coded as ‘syncope’ were reviewed and the diagnosis changed in six of them. Six out of the 11 deaths coded as ‘abdominal pain’ were reviewed, and all of them recoded. The West Midlands Strategic Health Authority, which had reason to worry since Mid-Staffs was not the only trust on its patch with a poor HSMR, responded in much the same way. It commissioned Richard Lilford and Mohammed Mohammed at Birmingham University to examine whether the cause of the problem could be a flaw in the way the HSMR was calculated.
Lilford and Mohammed had already begun to publish a series of articles attacking DFI’s approach, arguing that its tables wouldn’t achieve its stated aim of driving up the quality of care. Governments and regulators tend to make drastic interventions with the worst-performing institutions in mind, but the more effective strategy is probably to aim at improving average hospitals, since the ideas developed along the way will work almost anywhere. Lilford and Mohammed also criticised the use of the HSMR to measure quality of care. The HSMR shares the weaknesses of the HES data on which it based, but Lilford and Mohammed had a more fundamental criticism: mortality is unlikely to be a good measure of how good care is in a hospital. Typically, 98 per cent of in-patients survive their visit, so nearly all the data about what happens in a given hospital are ignored if we concentrate on mortality rates. Not only that, but of the 2 per cent who don’t survive, only a few will have died an ‘avoidable’ death, and it is only those deaths that can be used to measure the quality of care. Lilford and Mohammed carried out a set of simulations which showed that the HSMR is a reliable measure of quality of care only if the proportion of avoidable deaths is at least 15 per cent of the total. In other words, in a typical hospital with, say, 10,000 admissions a year, you might expect 200 patients to die. Unless at least 30 of those deaths are a result of the hospital’s mismanagement, that mismanagement won’t be picked up by the HSMR. This is a ludicrously high figure, Lilford and Mohammed thought, and proved that HSMR was simply a bad indicator.
Further, the HSMR was susceptible to bias: the measure would consistently favour some hospitals and penalise others. The ‘S’ is for ‘standardised’, and refers to the way the expected death rate is calculated from the profile of cases a given hospital deals with. Say two hospitals are equally good but hospital A has a high proportion of emergency admissions compared to hospital B. One might expect A to have a higher death rate than B. Jarman and Aylin would say they can still make a fair comparison because their measure takes the proportion of emergency admissions into account. But Lilford and Mohammed’s argument is more subtle. They say that while of course emergency admissions are more dangerous than other sorts, the degree of danger will vary. For example, if hospital A is in an area where many patients aren’t registered with a GP, a high proportion of relatively healthy patients might be admitted through A&E, but the HSMR will treat them as being at a risk equivalent to those admitted through A&Es in areas with better GP coverage, with the result that hospital A will incorrectly be given a higher expected mortality rate and a lower HSMR. Hospitals that are better at recording patients’ co-morbidities – the other diseases a patient has besides the one cited in the primary diagnosis – will also have a higher expected mortality, again making it easier to score well on the HSMR. Similar distortions appear, for example, in the case of hospitals that discharge an unusually high proportion of patients into hospices, since the mortality rate used in HSMR considers only patients who die in hospital, not those who die immediately after discharge.
This susceptibility to bias seems also to have been noticed by a competitor of DFI called CHKS, which describes itself as ‘a leading provider of healthcare intelligence and quality improvement services’. CHKS advised the Medway NHS Trust that it had been underusing the code for palliative care Z51.5. By increasing the proportion of patients it coded as receiving palliative care, Medway lowered its HSMR dramatically.
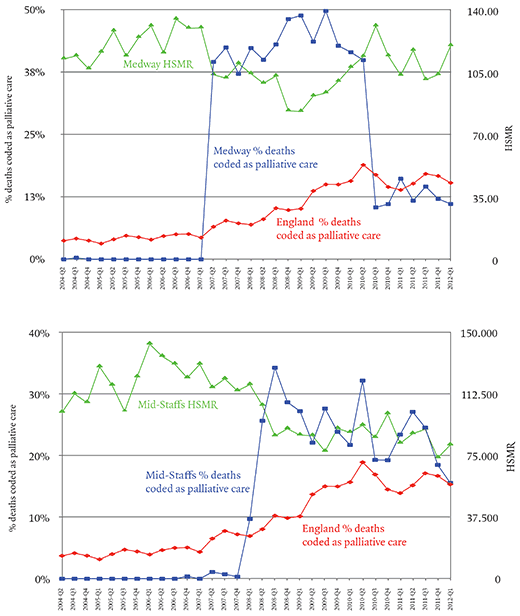
The first graph (above) shows that Medway’s use of Z51.5 went from zero to 40 per cent of deaths in three months and eventually as high as 50 per cent – that is to say, half of all the patients who died in the trust’s hospitals were classified as receiving palliative care. Mid-Staffs was not a client of this consultancy, and there is no evidence that it was influenced by CHKS, but a year later its use of the Z51.5 code also rose suddenly and dramatically.
Here the proportion of deaths coded as palliative care rose from zero in the last quarter of 2007 to 34 per cent in the third quarter of 2008. The impact on the trust’s HSMR can be seen in the second graph above: it falls below 100 for the first time since 1997. Jarman’s evidence to the Francis inquiry makes clear that he suspected Mid-Staffs was attempting to rig its HSMR; Francis found no evidence that there had been a deliberate attempt to do this, and considered various other possible explanations – a new coding manager, a change in government advice on the use of the code. None of these explanations seems quite to account for the transformation. As Jarman put it, the hospital seemed to have turned itself overnight into a specialist in terminal care. The timing was particularly suspicious because the changes coincided with the announcement in March 2008 of a Healthcare Commission inquiry into Mid-Staffs, in part because of the Cure the NHS campaign, but also because of concern over the trust’s mortality rates.
Jarman and Aylin rebutted the criticisms of their measure, arguing that it correlated with other indicators of quality of care and that the biases identified by Lilford and Mohammed make little difference. That HSMR is able to detect failing hospitals at all is perhaps because those hospitals are even worse than we imagined they could be. Between 2005 and 2008 the proportion of deaths at Mid-Staffs classed as avoidable (the difference between the actual and the expected number of deaths) was 18 per cent of the actual total, higher than the 15 per cent Lilford and Mohammed thought implausible. When you look at the Healthcare Commission’s account of the way the trust was run, it is easy to imagine how deaths on this kind of scale occurred.
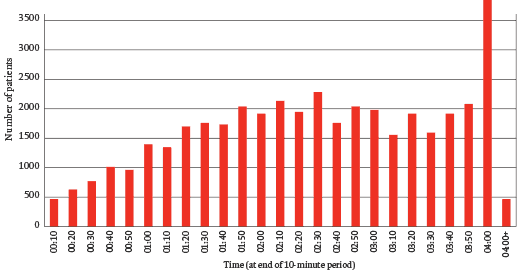
The chart above shows the distribution of waiting times in A&E in Stafford Hospital. There is an extraordinary peak at 3 hours 50 minutes: patients were being admitted in a hurry to avoid breaking government targets for a maximum of four-hour waits in A&E. That the system encouraged such sleight of hand is unsurprising – the data from many other hospitals would show a similar peak – but the problem at Stafford was that the care in A&E was poor. It was chronically understaffed, initial assessments were carried out by receptionists with no medical training, and essential equipment – cardiac monitors, for example – were missing or broken. Many patients admitted just before the deadline were sent to units where the care was even worse, some of them to an unstaffed ‘clinical decisions unit’, others to the so-called emergency assessment unit (EAU), a large ward described by the Healthcare Commission as poorly designed, busy, noisy, ‘chaotic’. Nurses in the EAU were inadequately trained and it was common for a patient’s condition to deteriorate unnoticed or for necessary medication not to be provided.
Calculations made according to Jarman and Aylin’s method suggest that over the three years from 2006 to 2008 between 391 and 595 more patients died than would have been expected. The difficulties with the HSMR mean that we can’t be sure that the real number falls within those limits, but what can be said with certainty is that there was enough evidence of a problem for someone to have done a bit more than merely changing the way deaths were coded.
The Mid-Staffs inquiry bears a remarkable similarity to the first major inquiry into serious problems at an NHS hospital, the Committee of Inquiry into Allegations of Ill-Treatment of Patients and Other Irregularities at the Ely Hospital, Cardiff in 1967. Problems at the hospital, a former workhouse with around six hundred patients, some of them mentally ill, most with learning difficulties, came to light when the News of the World sent Kenneth Robinson, then minister for health, a statement from a nursing assistant describing vulnerable patients being beaten, bullied, starved and robbed by nurses. Robinson ordered an independent inquiry, to be chaired by Geoffrey Howe, then a QC. One nurse, who carried a stick with which to threaten patients, was said to have bathed his patients by ordering them to strip in the hospital yard and turning a hose of cold water onto them. Howe found evidence to corroborate many of the specific accusations, and uncovered further evidence of disregard for patients (one witness said that when she asked a nurse for a patient’s dentures, the nurse took a set from the mouth of another patient as he slept). As with Mid-Staffs, it is the nurses’ actions that shock, and yet for Howe, as for Francis, it is the institution in which they worked, and the bodies that oversaw it, that bear most of the blame. Howe stated that the nursing assistant who broke the story was wrong to attribute the ill-treatment to ‘wilful or malicious misconduct’: we should be concerned instead with ‘the persistence of nursing methods which were old-fashioned, untutored, rough and, on some occasions, lacking in sympathy’.
The close parallels between Howe’s report and Francis’s were recently laid out by Kieran Walshe at the University of Manchester. Howe’s comments on the behaviour of nurses are echoed in Francis’s detection of ‘a systematic failure of the provision of good care’. Howe describes the inadequacy of systems for reporting incidents; Francis observed the same problem at Mid-Staffs. Howe thought the problems at Ely were partly caused by overcrowding; Francis concluded that staff/patient ratios at Mid-Staffs were too low. Howe’s inquiry revealed that staff who spoke out were victimised; Francis found that Mid-Staffs did not support the few whistleblowers who came forward. Howe described the nurses at Ely as having formed a close-knit, inward-looking community; Francis was surprised that in Mid-Staffs the trust and its staff seemed to have few outside contacts. The physician superintendent at Ely did too little to improve medical care; at Mid-Staffs the consultants by and large didn’t get involved in management. The principal responsibility for the shortcomings at Ely lay with the hospital management board; the deficient care at Mid-Staffs was the result of a collective failure on the part of the trust. The regional hospital board didn’t accept any responsibility for the supervision of standards at Ely; local and national oversight committees had failed to detect the problems in Mid-Staffs.
It would be easy to conclude from this that nothing was learned after 1967, but the Howe Report did have an effect. Mark Drakeford, a member of the Welsh Assembly and an academic who has written about the case, argues that the report was a significant boost to the movement to close hospitals such as Ely in favour of caring for their patients in the community. Darenth Park Hospital in Kent was the first large regional hospital for patients with learning disabilities to be closed, in 1973; Drakeford notes that the hospital board’s papers are clear that events at Ely influenced their decision. Howe’s report also resulted in the institution of a national system of hospital inspection, something doctors had opposed but which, in the wake of Ely, they were powerless to resist.
The Kennedy Report into Bristol Royal Infirmary observed that while it would be reassuring to believe that such a disaster could not happen again, ‘we cannot give that reassurance. Unless lessons are learned, it certainly could happen again.’ Jarman has said that after Bristol he felt there would be no excuse for anyone to say, as they had throughout the Kennedy inquiry, ‘with the benefit of hindsight’. Yet they do still say it: they said it, in fact, 378 times in the evidence presented to the Mid-Staffs inquiry. That the Mid-Staffs scandal happened at all might suggest that the Kennedy Report was less successful than Howe’s in changing practice, but the problems at Bristol and Mid-Staffs were different and it is in part because of the Bristol inquiry that data on hospital outcomes are now released and exposed to the scrutiny that helped prompt the Healthcare Commission’s investigation of Mid-Staffs.
It isn’t yet clear what, if anything, will be learned from the Francis Report. Cameron’s government has proposed a ‘friends and family’ test. This is a technique, popular with retail companies, for assessing customers’ perceptions of quality of service by asking if they would recommend your café, bicycle shop or paediatric cardiac surgery unit to their friends and family. Hospitals will have to get at least 15 per cent of patients to answer this question, and have been told that commissioners will be able to reward high-performing trusts. Given what we’ve learned about how managers respond to targets, it would be surprising if trusts weren’t already looking for wards or services which, given some extra attention, might yield more than their fair share of grateful respondents. If the test worked, it might help identify hospitals where nursing is poor, but it will be of less help in cases where patients are treated with a combination of kindness and technical incompetence – as at Bristol – or, as with Harold Shipman’s patients, ostensible kindness but actual malice. Just as important, most NHS scandals have affected patients who aren’t likely to voice their complaints, aren’t in a position to make choices and who often don’t have friends or family to speak up for them. Howe seems to have found his visit to the boys’ quarters at Ely particularly distressing. Most of the children didn’t go to school and spent their time in a bare dayroom whose constantly wetted furniture couldn’t be cleaned properly and where ‘little, if anything, was being done to interest the children in any kind of activity; it is not, therefore, surprising that they have little to do save fight amongst themselves and to destroy anything that they can get hold of.’ There were 129 children at the hospital, but the only complaints Howe received were from the parents of one child who had left and two who had been short-stay patients.
One of the striking revelations in the data discussed in the Francis Report is that although the HSMR at Mid-Staffs was consistently high, it wasn’t the highest. The media are now turning their attention to five other trusts with a high HSMR. (The measure is about to be superseded by a slightly adjusted version, called the Hospital-Level Mortality Indicator, published quarterly by the NHS Information Centre.) But there is no objective criterion one can use to identify a score as being too high. As ever, a difference in outcome between two treatments is declared ‘statistically significant’ if there is less than a 5 per cent chance that the difference could arise through random variations in the outcomes of treatments that are actually equally effective. By this standard, one can expect 5 per cent of clinical trials comparing equally effective (or ineffective) treatments to show a positive result in favour of one or the other; there are 166 acute trusts in England, so even if they are all equally good, eight of them would be branded as outliers using a 95 per cent threshold. DFI applies a 99.8 per cent confidence interval, which means many fewer outliers, but also that some poorly performing trusts are probably going undetected. The thinking here is influenced by work that Paul Aylin was commissioned to do by yet another public inquiry, that into the career of Harold Shipman. Aylin adopted an approach used in manufacturing to detect early signs of problems in production lines. The aim is to distinguish the rate of faults that occur when things are running as usual from a rate that might be an early sign of something malfunctioning. The metaphor of a single broken part in a system seemed to work in the Shipman case. It is less clear that we can use mortality rates to distinguish between a large group of trusts that are working normally and a small group that are going wrong.
A different approach is used in Australia. Queensland Health was the subject of two public inquiries in 2005 over its employment of a surgeon who became known to journalists as Dr Death. In response, it has adopted an approach which bears some similarities to the work of DFI: data are obtained from hospitals across the state and actual outcomes compared with expected outcomes in order to generate alerts. The focus is on performance over time rather than on a single number and, more important, the data are used differently. A broader range of outcomes is considered, not just mortality, and because it was argued that the threshold should be set very low, many hospitals are flagged so that investigations become a normal part of an institution’s commitment to safety. So long as NHS trusts that have a high HSMR continue to be named in the papers and the statistical concept of ‘avoidable death’ is interpreted as providing grounds for criminal prosecution, the argument for a similar system won’t be made here, let alone won, any time soon.
Send Letters To:
The Editor
London Review of Books,
28 Little Russell Street
London, WC1A 2HN
letters@lrb.co.uk
Please include name, address, and a telephone number.
